Data Mining, Machine Learning und KI

Herausforderungen großer Datenbestände
Industrie 4.0, Internet of Things, und System of Systems sind drei Schlagworte, welche zurzeit heiß diskutiert werden. Was diese drei Begriffe mit sich bringen, ist eine immer stärkere Vernetzung von Systemelementen und Systemen und damit die Generierung von immensen Datenmengen. Die Analyse dieser Datenberge stellt Unternehmen vor gravierenden Herausforderungen, denn es bedarf dazu u.a. spezieller statistischer Methoden. Es bietet für Unternehmen aber auch die Chance, Wettbewerbsvorteile zu generieren und konstantes Wachstum auch in Zukunft sicher zu stellen.
Definition von Big Data, Data Mining und Predictive Analytics
Der englischsprachige Begriff Big Data (von „groß“ und „Daten“) bezeichnet Datenmengen, welche zu groß sind, um sie mit manuellen und klassischen Methoden der Datenverarbeitung auszuwerten. Big Data ist häufig der Sammelbegriff für digitale Technologien, die in technischer Hinsicht für die neue Ära digitaler Kommunikation und Verarbeitung und in sozialer Hinsicht für den gesellschaftlichen Umbruch stehen.
Unter Data Mining versteht man die Extraktion von Wissen aus großen Datenmengen, welches bisher unbekannt, aber potentiell nützlich ist. Ziel ist es, mit systematischer Anwendung statistischer Verfahren Querverbindungen, Muster und Trends zu erkennen.
Als Predictive Analytics bezeichnet man auf Basis gesammelter Daten errechnete mathematische Modelle, welche es Systemen erlauben, Prognosen zu treffen. Bei Predictive Analytics Verfahren werden mathematische Modelle anhand eines Datensatzes trainiert und anschließend an einem unbekannten Datensatz validiert. Ziel ist es, dass dieser Algorithmus eine möglichst gute Anpassung an die zu erfüllende Aufgabe erreicht, um eine Vorhersage von Ereignissen zu ermöglichen. Anwendung findet Predictive Analytics vor allem im Bereich Machine Learning. Die bekanntesten Predictive Verfahren sind neuronale Netze und Ensemble Modelle.
Machine Learning und künstliche Intelligenz (KI)
Maschinelles Lernen oder Machine learning beschäftigt sich damit, Computern zu lehren, wie sie aus Daten lernen können, um darauf basierend Entscheidungen und Vorhersagen zu treffen. Das hierzu notwendige Wissen wird aus Erfahrung (mit Hilfe von Lerndaten) generiert, ohne dass der Computer explizit programmiert wird.
Die Kunst besteht wie auch bei Data Mining oder Predictive Analytics darin, Lerndaten nicht einfach auswendig zu lernen, sondern dahinterliegende Muster zu erkennen. Nur so wird „overfitting“ vermieden und erreicht, dass das System auch unbekannte Daten beurteilen kann.
Man kann maschinelles Lernen auch als Teilgebiet der künstlichen Intelligenz sehen. Der Begriff künstliche Intelligenz steht für die Bemühungen, menschenähnliche Entscheidungsstrukturen in einem nichteindeutigen Umfeld nachzubilden, d.h. einen Agenten so zu realisieren, dass er eigenständig Probleme bearbeiten kann. Dazu ist in den meisten Fällen (jedoch nicht immer) die Fähigkeit notwendig, Wissen aus Erfahrung zu generieren (= maschinelles Lernen).
Das Thema ist eng verwandt mit Data Mining und Predictive Analytics. Während Data Mining jedoch von einem Menschen in einer spezifischen Situation, an einem definierten Datenset angewandt wird, besteht das Ziel bei KI und Machine Learning in der Programmierung von intelligenten Agenten. Die Algorithmen und Methoden sind aber weitestgehend identisch.
Business Intelligence
Der Begriff Business Intelligence, Abkürzung BI, wurde ab Anfang bis Mitte der 1990er Jahre populär und bezeichnet Verfahren und Prozesse zur systematischen Analyse (Sammlung, Auswertung und Darstellung) von Daten in elektronischer Form. Ziel ist die Gewinnung von Erkenntnissen, die in Hinsicht auf die Unternehmensziele bessere operative oder strategische Entscheidungen ermöglichen.
Dies geschieht mit Hilfe analytischer Konzepte und entsprechender Software. Nun Bedarf es in einem Unternehmen einerseits Systeme zur Sammlung und Verwaltung von Daten wie Apache Hadoop. Darüber hinaus ist auch die dementsprechende Software zur Analyse dieser Daten notwendig. Die bekanntesten Software Tools für Data Mining sind JMP, Rapid Miner und R.
Das CRISP-DM Process Model als standardisierte Data Mining Vorgehensweise
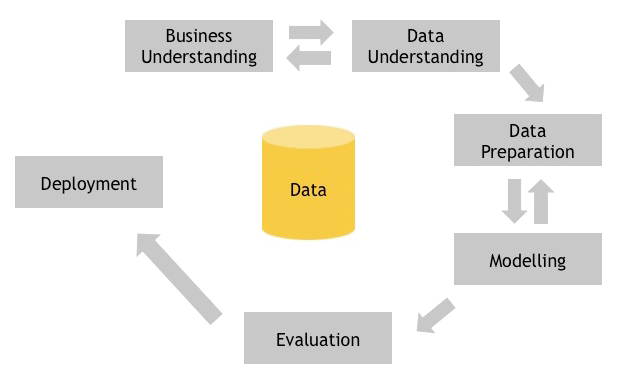
CRISP-DM steht für Cross-Industry Standard Process for Data Mining und ist ein Prozess Modell, welches der üblichen Vorgehensweise eines Data Mining Experten bzw. Data Scientist entsprechen sollte.
In der ersten Phase geht es um Business Understanding, also darum, das Projektziel aus Geschäftssicht zu verstehen und zu beschreiben. Wichtig ist hier, dass der Kunde und nicht der Data Mining Analyst seine Anforderungen beschreibt. Die Data Understanding Phase hat das Ziel, die anfänglich gesammelten Daten zu verstehen und hinsichtlich deren Qualität zu beurteilen. In der Data Preparation Phase wird der endgültige Datensatz aufbereitet, mit welchen in der Modeling Phase das mathematische Modell mit der besten Anpassung bestimmt wird. Bevor man in der Deployment Phase die Ergebnisse dem Kunden übergibt, müssen diese in der Evaluate Phase auf deren Eignung in der Anwendung überprüft werden.
Methodentrainings zu Data mining, maschinelles Lernen und KI
Bei unseren anwendungsorientierten Methodentrainings (z.B. die Ausbildung zum Data Mining Analyst) erhalten Sie einen Überblick über die gängigsten Tools und Methoden zum Thema Data Mining, Predictive Analytics, Maschine Learning und künstliche Intelligenz. Wir orientieren uns hierbei am CRISP-DM sowie anderen Vorgehensmodellen im Bereich maschinelles Lernen. Wir vermitteln statistische Verfahren wie Cluster Analyse, PCA, CART und neuronale Netze. Mit Hilfe von praxisnahen Fallbeispielen werden Ihnen die einzelnen Themengebiete spannend und interaktiv vermittelt. Entdecken und erlernen Sie bei uns die Tools für Data Mining, maschinelles Lernen und KI und werden Sie zum Profi für die Modellierung großer Datenbestände.